Hadaptive Use Case¶
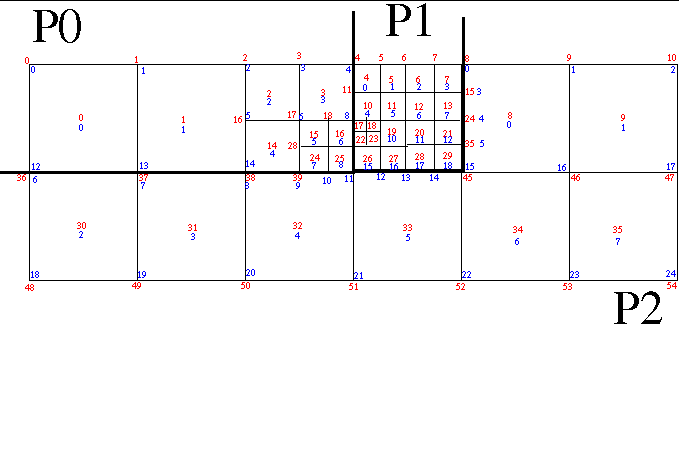
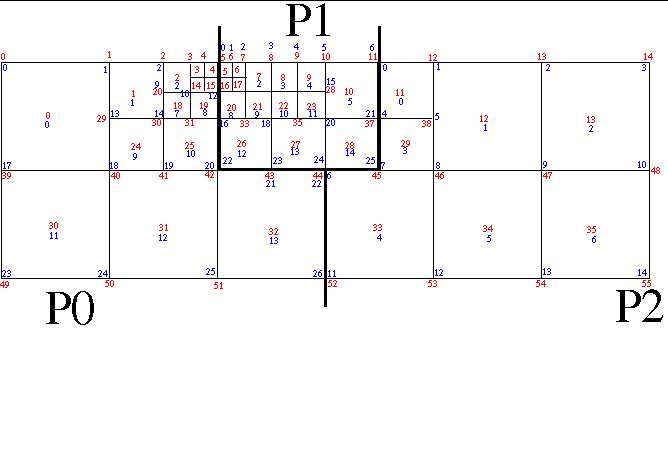
This is a simple example of using SAF to represent adaptation in a parallel-decomposed mesh. The use-case is hard-coded to write the 6 mesh states illustrated in “use case 5-1.gif”
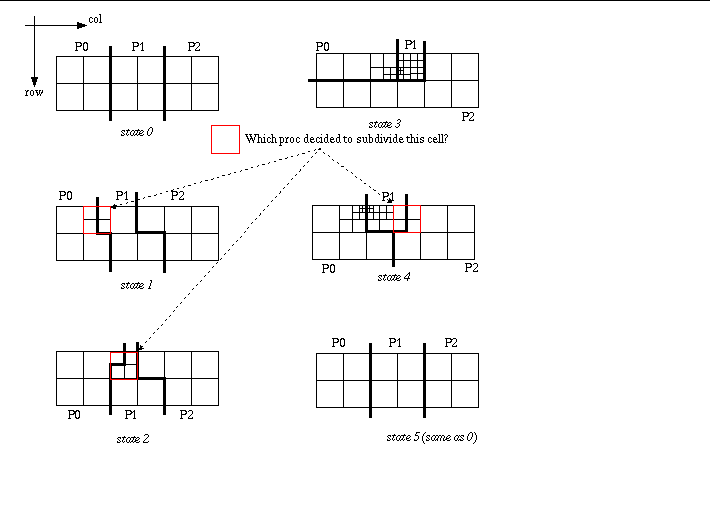
This example is designed to run on only 3 processors. It will abort with error if run in parallel on any other number of processors.
There are a total of 6 states output. The ending state is identical to the initial state. Other than a coordinate field, there are no other whole-mesh fields declared. This is simply due to expediency in completing this example code.
State 0
State 1
State 2
State 3
State 4
State 5
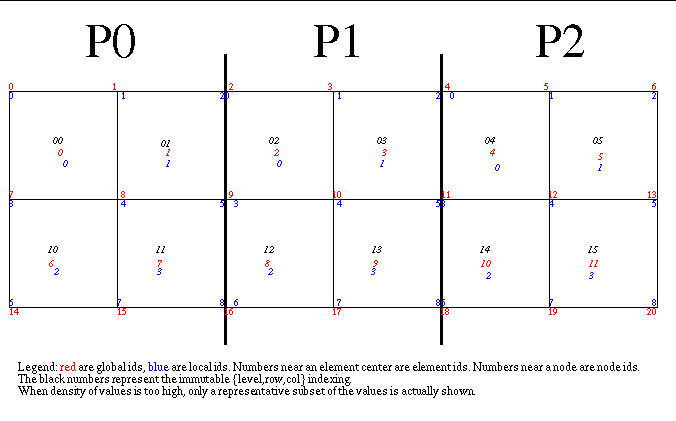
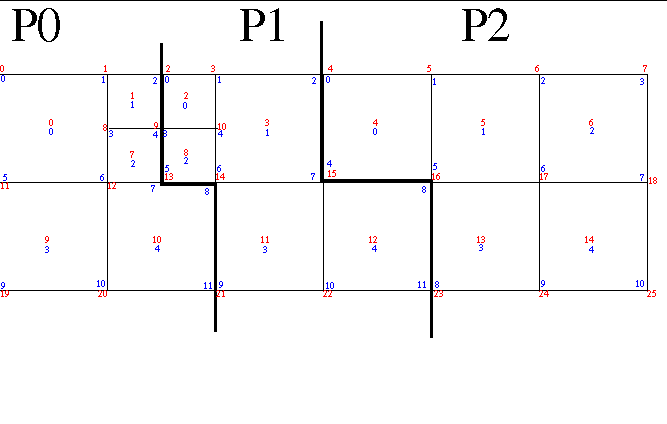
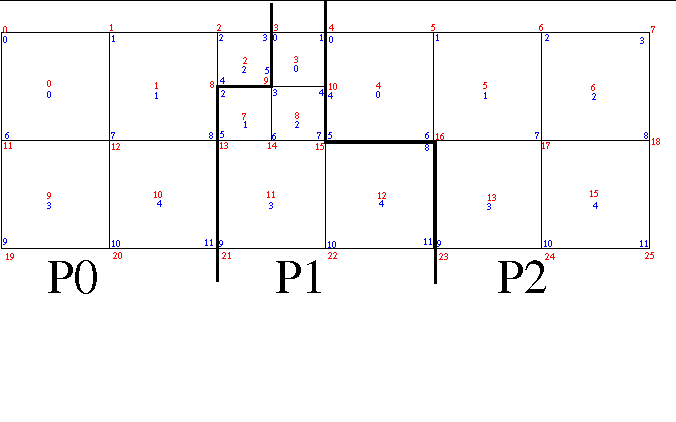
To give elements an immutable, global ID, we use something called the LRC index which is a triple of
the level of adaptivity and then the row and column index within that level starting from the origin
in the upper right. The larges elements are defined, arbitrarily, to be at level 1. So, for example, the
lower-right child of the one elment that is refined in state 1 has an LRC index of {2,1,3} for level 2,
row 1 and column 3. The LRC indexes are written on each step as alternative indexing for the elements.
In the dialog that follows, any reference to an element enclosed in ‘{‘ and ‘}’ braces is the element’s
LRC index.
In each state, each processor enumerates changes in the mesh relative to the last known dump of the
mesh to the database. Two broad categories of changes are tracked; refinements and re-balances. Refinements
are tracked and enumerated in the global context. Re-balancing is tracked and enumerated in the local
context. In other words, refinement information is stored above the processor decomposition while
re-balancing information is stored below it in the Subset Relation Graph (SRG). This was completely
arbitrary and can be changed if desired. Given all the elements on a processor at a given state, each
processor stores information to answer: “Which of my elements in the current state…”
1 2 | a. ...did I get from another processor in the last known state.
b. ...are children of (refinements of) an element in the last known state.
|
In addition, we arbitrarily choose to store information on UNrefinements and no-changes as well as elements that are kept (as opposed to re-balanced). There is no particular reason to do this other than trying to make the example a little more interesting. It costs more data that is non-essential.
In some cases, between two state dumps an element may be refined and some or all of its children may be re-balanced to other processors. When this happens, from the point of view of the database receiving information about each state, the convention used is that the processor in the previous state that owned the parent made the decision to refine it and then re-balanced the elements to other processors. For example, between state 0 and state 1 in “use case 5-1.gif”, element {1,0,1} which lived on processor 0 in state 0 was refined and half (2) of its children were given to processor 1. Thus, in state 1, processor 1 treats these two elements as being both refinements and re-balances.
Next, for re-balances, a field is stored on the re-balances set which identifies the processor from which each element in the set came.
[Side note: Why not store this information as a set of subsets? That too, is
completely appropriate. The approach chosen here is merely more convenient and storage efficient.
The fact is, there is a duality in how certain kinds of information can be captured in SAF. This duality is a
fundamental aspect of the mathematical interpreation of a field defined on member(s) of a Set Relation Graph
(SRG). In short, if one wishes to enumerate a value for each element in a collection, one has a choice of
saying (in natural language), “for each element, which value does it have…” or “for each value, which
elements have that value…”. The former approach takes the form of a field while the latter approach takes
the form of a set of subsets (a partition in fact). In fact, there is document that discusses these issues
in detail available from the SAF web-pages at www.ca.sandia.gov/ASCI/sdm/SAF/docs/wips/fields_n_maps.ps.gz
In summary, while one may have a natural way of thinking about this kind of data, there is clear
mathematical theory to explain why either approach is appropriate and there are even theoretical storage
and performance reasons to prefer one over the other depending on the situation. – end side note]
Since developing this initial use-case, a couple of enhancemenets have been identified that would be make the use-case more realistic and facilitate certain kinds of queries. First, we’ve identified a way to use SAF to capture differences in the sets from one state to the next as opposed or in addition to each specific state. Second, we’ve identified a way to make forward references (as apposed or in addition to to backward) to facilitate forward tracking of changes in refinement and rebalancing.
Issues: The ability to talk about the “difference” between two SRGs would be useful. If one is permitted only to enumerate a given state of the client’s data, it is difficult to store information at state I that captures what is changed in going to state I+1. For example, in going from state 0 to state 1, element {1,0,1} is refined into 4 children. However, the output for state 0 can’t mention any of these children because when state 0 is created, they don’t exist. Because they do exist in state 1, we can talk about where they came from relative to state 0. Thus, a causality is imposed, which the current implementation demonstrates, in the direction in which we can talk about changes (as mentioned above, I think we have identified as solution to this).
If one wishes to capture the differences between states, where does that information “live”? The
differences represent what happened in making the transition from one state to the next. In some sense
the differences represent actions on objects and not objects themselves. For example, “…these elments were
added by refinement of that element…” or “…these elements were obtained by rebalancing from that
processor…” are the kinds of statements one might like to make. It would be nice of such differences could
be captured using the existing objects available in SAF rather than having to create new ones. I think I have
identifed a way of doing this. Given two states, ‘a’ and ‘b’, and two sets, S and P where S is the subset of P
in both states, we can talk about the difference of Sa and Sb (that is S in state a and S in state b) in P
by introducing two subsets of S, one in state a, called Dab and one in state b called Dba where
1 2 | Dab = Sa - Sb (all points in Sa but not in Sb)
Dba = Sb - Sa (all points in Sb but not in Sa)
|
Together, these two sets represent, in effect, additions and deletions of points in going from Sa to Sb or vice versa. Dab is the set of points deleated from Sa in arriving at Sb and Dba is the set of points added to Sa in arriving at Sb (or deleted from Sb to arrive at Sa in the reverse direction).
Both Dab and Dba are ordinary subsets in their respective SRGs. However, what we are missing from SAF is
the ability to declare that Dab is a difference subset and which set it is differenced with. There
are two possible routes to take here. One is to simply add a SAF__DIFFERENCE option to the
:file:`saf_declare_subset_relation ../safapi_refman.rest/saf_declare_subset_relation.rst` call so that some subsets can be defined that are differences with other
sets. The other route is to add a new function to declare expressions involving sets such as…
saf_declare_set_expression``(``SAF__Set resultSet, char *expr) along with functions to build up the string
representation for the expression. This would then permit a client to find sets in the SRG according
to a given expression (implementation details would require something like an expr_blob_id member of a set
object in VBT which could be implemented as a meta_blob). The latter approach is more general in that
it permits a variety of set expressions to be characterized, not just a difference.
Because SAF is targeted primarily as a data modeling and I/O library, it is typically used to output
restart or plot dumps for states that are far apart relative to the physics time-step. For example,
there may be many hundreds of time-steps from one state dump to the next. Consequently, the relationships
that can be captured in such a scenario are how the two states as told to the**I/O**system are related.
For example, if a state is dumped at time I where an element, say K, is on processor 0 and then this
element migrates from processor 0, to 1, to 5, to 17 and finally to 22 before a new state is dumped to
the I/O system, the only fact that the I/O system can capture is that, somehow, element K on processor 0
was given to processor 22. In order to capture the in-between information, each of those states must be
enumerated to the I/O system. This might be where having the ability to enumerate state-transitions as
opposed to just states would be useful. Then, it may be relatively simple to enumerate each of the states
the code went through.